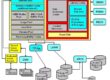
Oracle Database Memory Management
Memory management – focus is to maintain optimal sizes for memory structures.
- Memory is managed based on memory-related initialization parameters.
- These values are stored in the init.ora file for each database.
Three basic options for memory management are as follows:
- Automatic memory management:
- DBA specifies the target size for instance memory.
- The database instance automatically tunes to the target memory size.
- Database redistributes memory as needed between the SGA and the instance PGA.
- Automatic shared memory management:
- This management mode is partially automated.
- DBA specifies the target size for the SGA.
- DBA can optionally set an aggregate target size for the PGA or managing PGA work areas individually.
- Manual memory management:
- Instead of setting the total memory size, the DBA sets many initialization parameters to manage components of the SGA and instance PGA individually.
If you create a database with Database Configuration Assistant (DBCA) and choose the basic installation option, then automatic memory management is the default.
The memory structures include three areas of memory:
- System Global Area (SGA) – this is allocated when an Oracle Instance starts up.
- Program Global Area (PGA) – this is allocated when a Server Process starts up.
- User Global Area (UGA) – this is allocated when a user connects to create a session.
System Global Area
The SGA is a read/write memory area that stores information shared by all database processes and by all users of the database (sometimes it is called the Shared Global Area).
- This information includes both organizational data and control information used by the Oracle Server.
- The SGA is allocated in memory and virtual memory.
- The size of the SGA can be established by a DBA by assigning a value to the parameter SGA_MAX_SIZE in the parameter file—this is an optional parameter.
The SGA is allocated when an Oracle instance (database) is started up based on values specified in the initialization parameter file (either PFILE or SPFILE).
The SGA has the following mandatory memory structures:
- Database Buffer Cache
- Redo Log Buffer
- Java Pool
- Streams Pool
- Shared Pool – includes two components:
- Library Cache
- Data Dictionary Cache
- Other structures (for example, lock and latch management, statistical data)
Additional optional memory structures in the SGA include:
- Large Pool
The SHOW SGA SQL command will show you the SGA memory allocations.
- This is a recent clip of the SGA for the DBORCL database at SIUE.
- In order to execute SHOW SGA you must be connected with the special privilege SYSDBA (which is only available to user accounts that are members of the DBA Linux group).
SQL> connect / as sysdba
Connected.
SQL> show sga
Total System Global Area 1610612736 bytes
Fixed Size 2084296 bytes
Variable Size 1006633528 bytes
Database Buffers 587202560 bytes
Redo Buffers 14692352 bytes
Early versions of Oracle used a Static SGA. This meant that if modifications to memory management were required, the database had to be shutdown, modifications were made to the init.ora parameter file, and then the database had to be restarted.
Oracle 11g uses a Dynamic SGA. Memory configurations for the system global area can be made without shutting down the database instance. The DBA can resize the Database Buffer Cache and Shared Pool dynamically.
Several initialization parameters are set that affect the amount of random access memory dedicated to the SGA of an Oracle Instance. These are:
- SGA_MAX_SIZE: This optional parameter is used to set a limit on the amount of virtual memory allocated to the SGA – a typical setting might be 1 GB; however, if the value for SGA_MAX_SIZE in the initialization parameter file or server parameter file is less than the sum the memory allocated for all components, either explicitly in the parameter file or by default, at the time the instance is initialized, then the database ignores the setting for SGA_MAX_SIZE. For optimal performance, the entire SGA should fit in real memory to eliminate paging to/from disk by the operating system.
- DB_CACHE_SIZE: This optional parameter is used to tune the amount memory allocated to the Database Buffer Cache in standard database blocks. Block sizes vary among operating systems. The DBORCL database uses 8 KB blocks. The total blocks in the cache defaults to 48 MB on LINUX/UNIX and 52 MB on Windows operating systems.
- LOG_BUFFER: This optional parameter specifies the number of bytes allocated for the Redo Log Buffer.
- SHARED_POOL_SIZE: This optional parameter specifies the number of bytes of memory allocated to shared SQL and PL/SQL. The default is 16 MB. If the operating system is based on a 64 bit configuration, then the default size is 64 MB.
- LARGE_POOL_SIZE: This is an optional memory object – the size of the Large Pool defaults to zero. If the init.ora parameter PARALLEL_AUTOMATIC_TUNING is set to TRUE, then the default size is automatically calculated.
- JAVA_POOL_SIZE: This is another optional memory object. The default is 24 MB of memory.
The size of the SGA cannot exceed the parameter SGA_MAX_SIZE minus the combination of the size of the additional parameters, DB_CACHE_SIZE, LOG_BUFFER, SHARED_POOL_SIZE, LARGE_POOL_SIZE, and JAVA_POOL_SIZE.
Memory is allocated to the SGA as contiguous virtual memory in units termed granules. Granule size depends on the estimated total size of the SGA, which as was noted above, depends on the SGA_MAX_SIZE parameter. Granules are sized as follows:
- If the SGA is less than 1 GB in total, each granule is 4 MB.
- If the SGA is greater than 1 GB in total, each granule is 16 MB.
Granules are assigned to the Database Buffer Cache, Shared Pool, Java Pool, and other memory structures, and these memory components can dynamically grow and shrink. Using contiguous memory improves system performance. The actual number of granules assigned to one of these memory components can be determined by querying the database view named
V$BUFFER_POOL.
Granules are allocated when the Oracle server starts a database instance in order to provide memory addressing space to meet the SGA_MAX_SIZE parameter. The minimum is 3 granules: one each for the fixed SGA, Database Buffer Cache, and Shared Pool. In practice, you’ll find the SGA is allocated much more memory than this. The SELECT statement shown below shows a current_size of 1,152 granules.
SELECT name, block_size, current_size, prev_size, prev_buffers
FROM v$buffer_pool;
NAME BLOCK_SIZE CURRENT_SIZE PREV_SIZE PREV_BUFFERS
——————– ———- ———— ———- ————
DEFAULT 8192 560 576 71244
For additional information on the dynamic SGA sizing, enroll in Oracle’s Oracle11g Database Performance Tuning course.
Program Global Area (PGA)
A PGA is:
- a nonshared memory region that contains data and control information exclusively for use by an Oracle process.
- A PGA is created by Oracle Database when an Oracle process is started.
- One PGA exists for each Server Process and each Background Process. It stores data and control information for a single Server Process or a single Background Process.
- It is allocated when a process is created and the memory is scavenged by the operating system when the process terminates. This is NOT a shared part of memory – one PGA to each process only.
- The collection of individual PGAs is the total instance PGA, or instance PGA.
- Database initialization parameters set the size of the instance PGA, not individual PGAs.
The Program Global Area is also termed the Process Global Area (PGA) and is a part of memory allocated that is outside of the Oracle Instance.
The content of the PGA varies, but as shown in the figure above, generally includes the following:
- Private SQL Area: Stores information for a parsed SQL statement – stores bind variable values and runtime memory allocations. A user session issuing SQL statements has a Private SQL Area that may be associated with a Shared SQL Area if the same SQL statement is being executed by more than one system user. This often happens in OLTP environments where many users are executing and using the same application program.
- Dedicated Server environment – the Private SQL Area is located in the Program Global Area.
- Shared Server environment – the Private SQL Area is located in the System Global Area.
- Session Memory: Memory that holds session variables and other session information.
- SQL Work Areas: Memory allocated for sort, hash-join, bitmap merge, and bitmap create types of operations.
- Oracle 9i and later versions enable automatic sizing of the SQL Work Areas by setting the WORKAREA_SIZE_POLICY = AUTO parameter (this is the default!) and PGA_AGGREGATE_TARGET = n (where n is some amount of memory established by the DBA). However, the DBA can let the Oracle DBMS determine the appropriate amount of memory.
User Global Area
The User Global Area is session memory.
A session that loads a PL/SQL package into memory has the package state stored to the UGA. The package state is the set of values stored in all the package variables at a specific time. The state changes as program code the variables. By default, package variables are unique to and persist for the life of the session.
The OLAP page pool is also stored in the UGA. This pool manages OLAP data pages, which are equivalent to data blocks. The page pool is allocated at the start of an OLAP session and released at the end of the session. An OLAP session opens automatically whenever a user queries a dimensional object such as a cube.
Note: Oracle OLAP is a multidimensional analytic engine embedded in Oracle Database 11g. Oracle OLAP cubes deliver sophisticated calculations using simple SQL queries – producing results with speed of thought response times.
The UGA must be available to a database session for the life of the session. For this reason, the UGA cannot be stored in the PGA when using a shared server connection because the PGA is specific to a single process. Therefore, the UGA is stored in the SGA when using shared server connections, enabling any shared server process access to it. When using a dedicated server connection, the UGA is stored in the PGA.
Automatic Shared Memory Management
Prior to Oracle 10G, a DBA had to manually specify SGA Component sizes through the initialization parameters, such as SHARED_POOL_SIZE, DB_CACHE_SIZE, JAVA_POOL_SIZE, and LARGE_POOL_SIZE parameters.
Automatic Shared Memory Management enables a DBA to specify the total SGA memory available through the SGA_TARGET initialization parameter. The Oracle Database automatically distributes this memory among various subcomponents to ensure most effective memory utilization.
The DBORCL database SGA_TARGET is set in the initDBORCL.ora file:
sga_target=1610612736
With automatic SGA memory management, the different SGA components are flexibly sized to adapt to the SGA available.
Setting a single parameter simplifies the administration task – the DBA only specifies the amount of SGA memory available to an instance – the DBA can forget about the sizes of individual components. No out of memory errors are generated unless the system has actually run out of memory. No manual tuning effort is needed.
The SGA_TARGET initialization parameter reflects the total size of the SGA and includes memory for the following components:
- Fixed SGA and other internal allocations needed by the Oracle Database instance
- The log buffer
- The shared pool
- The Java pool
- The buffer cache
- The keep and recycle buffer caches (if specified)
- Nonstandard block size buffer caches (if specified)
- The Streams Pool
If SGA_TARGET is set to a value greater than SGA_MAX_SIZE at startup, then the SGA_MAX_SIZE value is bumped up to accommodate SGA_TARGET.
When you set a value for SGA_TARGET, Oracle Database 11g automatically sizes the most commonly configured components, including:
- The shared pool (for SQL and PL/SQL execution)
- The Java pool (for Java execution state)
- The large pool (for large allocations such as RMAN backup buffers)
- The buffer cache
There are a few SGA components whose sizes are not automatically adjusted. The DBA must specify the sizes of these components explicitly, if they are needed by an application. Such components are:
- Keep/Recycle buffer caches (controlled by DB_KEEP_CACHE_SIZE and DB_RECYCLE_CACHE_SIZE)
- Additional buffer caches for non-standard block sizes (controlled by DB_nK_CACHE_SIZE, n = {2, 4, 8, 16, 32})
- Streams Pool (controlled by the new parameter STREAMS_POOL_SIZE)
The granule size that is currently being used for the SGA for each component can be viewed in the view V$SGAINFO. The size of each component and the time and type of the last resize operation performed on each component can be viewed in the view V$SGA_DYNAMIC_COMPONENTS.
SQL> select * from v$sgainfo;
More…
NAME BYTES RES
——————————– ———- —
Fixed SGA Size 2084296 No
Redo Buffers 14692352 No
Buffer Cache Size 587202560 Yes
Shared Pool Size 956301312 Yes
Large Pool Size 16777216 Yes
Java Pool Size 33554432 Yes93
Streams Pool Size 0 Yes
Granule Size 16777216 No
Maximum SGA Size 1610612736 No
Startup overhead in Shared Pool 67108864 No
Free SGA Memory Available 0
11 rows selected.
Shared Pool
The Shared Pool is a memory structure that is shared by all system users.
- It caches various types of program data. For example, the shared pool stores parsed SQL, PL/SQL code, system parameters, and data dictionary information.
- The shared pool is involved in almost every operation that occurs in the database. For example, if a user executes a SQL statement, then Oracle Database accesses the shared pool.
- It consists of both fixed and variable structures.
- The variable component grows and shrinks depending on the demands placed on memory size by system users and application programs.
Memory can be allocated to the Shared Pool by the parameter SHARED_POOL_SIZE in the parameter file. The default value of this parameter is 8MB on 32-bit platforms and 64MB on 64-bit platforms. Increasing the value of this parameter increases the amount of memory reserved for the shared pool.
You can alter the size of the shared pool dynamically with the ALTER SYSTEM SET command. An example command is shown in the figure below. You must keep in mind that the total memory allocated to the SGA is set by the SGA_TARGET parameter (and may also be limited by the SGA_MAX_SIZE if it is set), and since the Shared Pool is part of the SGA, you cannot exceed the maximum size of the SGA. It is recommended to let Oracle optimize the Shared Pool size.
The Shared Pool stores the most recently executed SQL statements and used data definitions. This is because some system users and application programs will tend to execute the same SQL statements often. Saving this information in memory can improve system performance.
The Shared Pool includes several cache areas described below.
Library Cache
Memory is allocated to the Library Cache whenever an SQL statement is parsed or a program unit is called. This enables storage of the most recently used SQL and PL/SQL statements.
If the Library Cache is too small, the Library Cache must purge statement definitions in order to have space to load new SQL and PL/SQL statements. Actual management of this memory structure is through a Least-Recently-Used (LRU) algorithm. This means that the SQL and PL/SQL statements that are oldest and least recently used are purged when more storage space is needed.
The Library Cache is composed of two memory subcomponents:
- Shared SQL: This stores/shares the execution plan and parse tree for SQL statements, as well as PL/SQL statements such as functions, packages, and triggers. If a system user executes an identical statement, then the statement does not have to be parsed again in order to execute the statement.
- Private SQL Area: With a shared server, each session issuing a SQL statement has a private SQL area in its PGA.
- Each user that submits the same statement has a private SQL area pointing to the same shared SQL area.
- Many private SQL areas in separate PGAs can be associated with the same shared SQL area.
- This figure depicts two different client processes issuing the same SQL statement – the parsed solution is already in the Shared SQL Area.
Data Dictionary Cache
The Data Dictionary Cache is a memory structure that caches data dictionary information that has been recently used.
- This cache is necessary because the data dictionary is accessed so often.
- Information accessed includes user account information, datafile names, table descriptions, user privileges, and other information.
The database server manages the size of the Data Dictionary Cache internally and the size depends on the size of the Shared Pool in which the Data Dictionary Cache resides. If the size is too small, then the data dictionary tables that reside on disk must be queried often for information and this will slow down performance.
Server Result Cache
The Server Result Cache holds result sets and not data blocks. The server result cache contains the SQL query result cache and PL/SQL function result cache, which share the same infrastructure.
SQL Query Result Cache
This cache stores the results of queries and query fragments.
- Using the cache results for future queries tends to improve performance.
- For example, suppose an application runs the same SELECT statement repeatedly. If the results are cached, then the database returns them immediately.
- In this way, the database avoids the expensive operation of rereading blocks and recomputing results.
PL/SQL Function Result Cache
The PL/SQL Function Result Cache stores function result sets.
- Without caching, 1000 calls of a function at 1 second per call would take 1000 seconds.
- With caching, 1000 function calls with the same inputs could take 1 second total.
- Good candidates for result caching are frequently invoked functions that depend on relatively static data.
- PL/SQL function code can specify that results be cached.
Buffer Caches
A number of buffer caches are maintained in memory in order to improve system response time.
Database Buffer Cache
The Database Buffer Cache is a fairly large memory object that stores the actual data blocks that are retrieved from datafiles by system queries and other data manipulation language commands.
The purpose is to optimize physical input/output of data.
When Database Smart Flash Cache (flash cache) is enabled, part of the buffer cache can reside in the flash cache.
- This buffer cache extension is stored on a flash disk device, which is a solid state storage device that uses flash memory.
- The database can improve performance by caching buffers in flash memory instead of reading from magnetic disk.
- Database Smart Flash Cache is available only in Solaris and Oracle Enterprise Linux.
A query causes a Server Process to look for data.
- The first look is in the Database Buffer Cache to determine if the requested information happens to already be located in memory – thus the information would not need to be retrieved from disk and this would speed up performance.
- If the information is not in the Database Buffer Cache, the Server Process retrieves the information from disk and stores it to the cache.
- Keep in mind that information read from disk is read a block at a time, NOT a row at a time, because a database block is the smallest addressable storage space on disk.
Database blocks are kept in the Database Buffer Cache according to a Least Recently Used (LRU) algorithm and are aged out of memory if a buffer cache block is not used in order to provide space for the insertion of newly needed database blocks.
There are three buffer states:
- Unused – a buffer is available for use – it has never been used or is currently unused.
- Clean – a buffer that was used earlier – the data has been written to disk.
- Dirty – a buffer that has modified data that has not been written to disk.
Each buffer has one of two access modes:
- Pinned – a buffer is pinned so it does not age out of memory.
- Free (unpinned).
The buffers in the cache are organized in two lists:
- the write list and,
- the least recently used (LRU) list.
The write list (also called a write queue) holds dirty buffers – these are buffers that hold that data that has been modified, but the blocks have not been written back to disk.
The LRU list holds unused, free clean buffers, pinned buffers, and free dirty buffers that have not yet been moved to the write list. Free clean buffers do not contain any useful data and are available for use. Pinned buffers are currently being accessed.
When an Oracle process accesses a buffer, the process moves the buffer to the most recently used (MRU) end of the LRU list – this causes dirty buffers to age toward the LRU end of the LRU list.
When an Oracle user process needs a data row, it searches for the data in the database buffer cache because memory can be searched more quickly than hard disk can be accessed. If the data row is already in the cache (a cache hit), the process reads the data from memory; otherwise a cache miss occurs and data must be read from hard disk into the database buffer cache.
Before reading a data block into the cache, the process must first find a free buffer. The process searches the LRU list, starting at the LRU end of the list. The search continues until a free buffer is found or until the search reaches the threshold limit of buffers.
Each time a user process finds a dirty buffer as it searches the LRU, that buffer is moved to the write list and the search for a free buffer continues.
When a user process finds a free buffer, it reads the data block from disk into the buffer and moves the buffer to the MRU end of the LRU list.
If an Oracle user process searches the threshold limit of buffers without finding a free buffer, the process stops searching the LRU list and signals the DBWn background process to write some of the dirty buffers to disk. This frees up some buffers.
Database Buffer Cache Block Size
The block size for a database is set when a database is created and is determined by the init.ora parameter file parameter named DB_BLOCK_SIZE.
- Typical block sizes are 2KB, 4KB, 8KB, 16KB, and 32KB.
- The size of blocks in the Database Buffer Cache matches the block size for the database.
- The DBORCL database uses an 8KB block size.
Because tablespaces that store oracle tables can use different (non-standard) block sizes, there can be more than one Database Buffer Cache allocated to match block sizes in the cache with the block sizes in the non-standard tablespaces.
The size of the Database Buffer Caches can be controlled by the parameters DB_CACHE_SIZE and DB_nK_CACHE_SIZE to dynamically change the memory allocated to the caches without restarting the Oracle instance.
You can dynamically change the size of the Database Buffer Cache with the ALTER SYSTEM command like the one shown here:
ALTER SYSTEM SET DB_CACHE_SIZE = 96M;
You can have the Oracle Server gather statistics about the Database Buffer Cache to help you size it to achieve an optimal workload for the memory allocation. This information is displayed from the V$DB_CACHE_ADVICE view. In order for statistics to be gathered, you can dynamically alter the system by using the ALTER SYSTEM SET DB_CACHE_ADVICE (OFF, ON, READY) command. However, gathering statistics on system performance always incurs some overhead that will slow down system performance.
SQL> ALTER SYSTEM SET db_cache_advice = ON;
System altered.
SQL> DESC V$DB_cache_advice;
Name Null? Type
—————————————– ——– ————-
ID NUMBER
NAME VARCHAR2(20)
BLOCK_SIZE NUMBER
ADVICE_STATUS VARCHAR2(3)
SIZE_FOR_ESTIMATE NUMBER
SIZE_FACTOR NUMBER
BUFFERS_FOR_ESTIMATE NUMBER
ESTD_PHYSICAL_READ_FACTOR NUMBER
ESTD_PHYSICAL_READS NUMBER
ESTD_PHYSICAL_READ_TIME NUMBER
ESTD_PCT_OF_DB_TIME_FOR_READS NUMBER
ESTD_CLUSTER_READS NUMBER
ESTD_CLUSTER_READ_TIME NUMBER
SQL> SELECT name, block_size, advice_status FROM v$db_cache_advice;
NAME BLOCK_SIZE ADV
——————– ———- —
DEFAULT 8192 ON
<more rows will display>
21 rows selected.
SQL> ALTER SYSTEM SET db_cache_advice = OFF;
System altered.
KEEP Buffer Pool
This pool retains blocks in memory (data from tables) that are likely to be reused throughout daily processing. An example might be a table containing user names and passwords or a validation table of some type.
The DB_KEEP_CACHE_SIZE parameter sizes the KEEP Buffer Pool.
RECYCLE Buffer Pool
This pool is used to store table data that is unlikely to be reused throughout daily processing – thus the data blocks are quickly removed from memory when not needed.
The DB_RECYCLE_CACHE_SIZE parameter sizes the Recycle Buffer Pool.
Redo Log Buffer
The Redo Log Buffer memory object stores images of all changes made to database blocks.
- Database blocks typically store several table rows of organizational data. This means that if a single column value from one row in a block is changed, the block image is stored. Changes include INSERT, UPDATE, DELETE, CREATE, ALTER, or DROP.
- LGWR writes redo sequentially to disk while DBWn performs scattered writes of data blocks to disk.
- Scattered writes tend to be much slower than sequential writes.
- Because LGWR enable users to avoid waiting for DBWn to complete its slow writes, the database delivers better performance.
The Redo Log Buffer as a circular buffer that is reused over and over. As the buffer fills up, copies of the images are stored to the Redo Log Files that are covered in more detail in a later module.
Large Pool
The Large Pool is an optional memory structure that primarily relieves the memory burden placed on the Shared Pool. The Large Pool is used for the following tasks if it is allocated:
- Allocating space for session memory requirements from the User Global Area where a Shared Server is in use.
- Transactions that interact with more than one database, e.g., a distributed database scenario.
- Backup and restore operations by the Recovery Manager (RMAN) process.
- RMAN uses this only if the BACKUP_DISK_IO = n and BACKUP_TAPE_IO_SLAVE = TRUE parameters are set.
- If the Large Pool is too small, memory allocation for backup will fail and memory will be allocated from the Shared Pool.
- Parallel execution message buffers for parallel server operations. The PARALLEL_AUTOMATIC_TUNING = TRUE parameter must be set.
The Large Pool size is set with the LARGE_POOL_SIZE parameter – this is not a dynamic parameter. It does not use an LRU list to manage memory.
Java Pool
The Java Pool is an optional memory object, but is required if the database has Oracle Java installed and in use for Oracle JVM (Java Virtual Machine).
- The size is set with the JAVA_POOL_SIZE parameter that defaults to 24MB.
- The Java Pool is used for memory allocation to parse Java commands and to store data associated with Java commands.
- Storing Java code and data in the Java Pool is analogous to SQL and PL/SQL code cached in the Shared Pool.
Streams Pool
This pool stores data and control structures to support the Oracle Streams feature of Oracle Enterprise Edition.
- Oracle Steams manages sharing of data and events in a distributed environment.
- It is sized with the parameter STREAMS_POOL_SIZE.
- If STEAMS_POOL_SIZE is not set or is zero, the size of the pool grows dynamically.